看过《Wall-E》的小伙伴们应该还记得那令人动容的一幕:电影的主角---小机器人Wall-E---在黑夜中独自仰望星空,憧憬着繁星和爱情。也许你也曾向往着拥有这样的一个小家伙和你一起观天赏月共享韶华。
其实,天文学家们早已开始着手训练机器了,但是我们训练机器的目的并不是为了制造出一个可以对酒当歌的伙伴,而是在即将到来的大数据天体物理时代,天文学家们必须依靠机器学习的方法来实现宇量的数据处理工作。
1. 为什么天文学家需要机器学习?
随着观测技术的发展,天文数据呈指数型增长。例如,著名的斯隆巡天(The Sloan Digital Sky Survey, https://www.sdss.org/)开始于2000年,观测到了约300万个天体,数据量大约是40TB(1TB=1024GB)。而目前正在运行的暗能量巡天(The Dark Energy Survey,https://www.darkenergysurvey.org/)的数据量至少是斯隆巡天的100倍。未来欧洲的欧几里得巡天(Euclid,https://www.euclid-ec.org/)以及美国的大尺度概要巡天(LSST,https://www.lsst.org/)则会把数据量推到惊人的50PB和200PB(1PB=1024TB)。
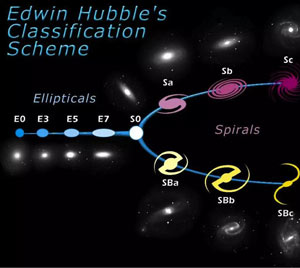
只观测星系一种天体的样本数目就将达到数十亿,因此以往传统编程加人工的处理方式的效率已经不足以应付这样庞大的数据量了。例如,最基本的把上百亿的星系按照哈勃星系图表(图1)分类的工作量就多到让人望而却步。那时候,高效的自动化数据处理将成为刚需。幸好人工智能技术在过去的十几年里有了突飞猛进的发展,比如图样识别技术已经可以快速地把互联网上的图片进行分类了。天文学家们受此启发,开始把人工智能领域里的相关技术应用到天文数据的自动化处理中。

图1 哈勃星系分类图表 图片来源:https://en.wikipedia.org/wiki/Hubble_sequence
2. 什么是机器学习
著名科学家赫伯特·西蒙(Herbert Simon,1975年图灵奖和1978年诺贝尔经济学奖得主)给机器学习下过定义:机器学习是计算机程序通过摄取数据来自行改进性能的过程。
机器学习和传统程序根本的不同就是编程逻辑,机器学习的理念是归纳法,而传统编程更倾向于演绎法。例如,如果想用传统编程方法对星系的形状分类,我们需先测量星系的形状参数,然后设定阈值,再根据形状参数和阈值的关系对星系分类;而机器学习的逻辑则是先建立一个普适的模型,不提供特定参数或阈值,只输入星系图像和归类标签,这个模型就会根据输入的数据自我调整,从而演化成一个可用于星系形状分类的分类器。图2展示了传统程序和机器学习程序工作流程的差异。
打个比方,传统编程就像是说走就走的旅行,有路我就去尝试,终点在哪里我不确定;而机器学习则更像是出差,起点和终点都是已知的,机器学习程序会生成一个最优的途径给我们。前者适合于探索未知,而后者则更有助于解决明确的问题。

图2 传统编程和机器学习编程逻辑的差异
从运行方式上讲,机器学习主要分为监督学习、非监督学习、和强化学习。监督学习是指在有明确训练样本的情况下,应用训练样本中的数据(如图片)和标签(分类标签如猫或数字标签如0.7)来演化出所需模型。监督学习多用于分类和预测,例如,根据图片特征辨别动物种类和根据卫星云图预测降水概率。
非监督学习是指在不提供标签的情况下,程序根据数据的特征把数据归入不同的分组中。非监督学习多用于寻找相关对象和异常情况预警,例如,新闻分类和新物种发现提醒。
强化学习要比前两个更加复杂一些,它是通过感知、行为、奖励的循环模拟人或动物的学习过程。大名鼎鼎的AlphaGo就是基于强化学习的工作原理在围棋场上击败了李世石的。
如果把机器比作一个婴儿,监督学习就是你先告诉他什么是苹果,什么是梨,然后给他多张卡片让他分出苹果和梨;非监督学习则是先不告诉他什么是苹果,什么是梨,直接给他多张卡片让他把相同的放在一组里;而强化学习是什么都不告诉他,让他自己探索你所提供的卡片,他若主动把卡片进行正确的分类,则给予其奖励,多次循环后完成卡片的分类。目前,在天文学领域里,应用比较广泛的是监督学习和非监督学习。
3. 机器学习在天体物理中的应用
监督学习在天体物理中的应用最为广泛,包括星系形状分类(图3),特定目标查找(图4),快速自动化建模(图5)等等。我在对应的图例中列出了上述应用的简介,如果您想了解更深层次的细节,还可阅读图例中的参考文献。

图3 应用机器学习进行星系形状分类的范例。每一行是被分到同一组的星系图像,每一列代表着不同的形状分组,例如,第一行代表着离我们比较远的盘状星系,中间一行则为大质量的椭圆星系,最后一行是离我们比较近的漩涡星系。监督学习(参考文献:http://adsabs.harvard.edu/abs/2015MNRAS.450.1441D)和非监督学习(参考文献:http://adsabs.harvard.edu/abs/2018MNRAS.473.1108H)都能很好地胜任这类工作,而且在准确率都不输于传统方法的前提下,大大提高了分类速度。

图4 宇宙中星系尺度的爱因斯坦环现象的范例。图中所示的蓝色环结构是广义相对论所预言『爱因斯坦环』结构,天文学家们可以通过这些环结构的形状来研究星系中暗物质的质量分布。但是这种结构在宇宙中比较稀少,例如图中所示的爱因斯坦环查找项目(SLACS)中,SLACS团队搜索了二十万个星系,但只找到了大约20个如图所示的爱因斯坦环系统(参考文献:https://ui.adsabs.harvard.edu/abs/2008ApJ...682..964B)。在LSST和Euclid时代,天文学家们预言我们会从几十亿个星系中找到上万个这样的系统,面对如此大的工作量,我们已经开始尝试引入机器学习的方法来实现这一目标了(参考文献:https://ui.adsabs.harvard.edu/abs/2019A%26A...625A.119M)。图片来源:NASA/ESA/A. Bolton

图5 应用机器学习解决回归问题的实例。左图为宇宙中的投影物质分布示意图(参考文献:https://astrostatistics.psu.edu/scma4/Bernstein.pdf),右图为机器学习的方法根据宇宙中的投影物质分布预言的宇宙学参数(参考文献:http://adsabs.harvard.edu/abs/2018PhRvD..98l3518F),其中蓝色区域为机器学习的结果,红色区域为传统方法,图形的面积代表测量的不确定性,可以直观的看出机器学习结果的不确定性更小。这个应用的基本思想是通过机器学习的算法建立起左图和由图中宇宙学参数的对应关系,这样在将来有新的物质分布的数据的时候,只要输入训练好的模型中,就可以快速地返回对应的宇宙学参数了。
监督学习的最大优点就是目的性强和准确率高,但其缺点同样突出。例如,预言结果高度依赖训练样本的性质,而且针对不同望远镜和不同的观测目的,天文学家们需要生成特定性质的训练样本,此过程工作量巨大,其中还包含很多重复性的工作。当前,在研究如何把监督学习应用到天文数据的时候,天文学家们很大的一部分精力都放在如何生成逼真的仿真数据(图6),为的是尽量避免监督学习的预言对于真实值的偏离。

图6 机器学习算法生成的仿真星系图像与真实图像的对比(参考文献:https://ui.adsabs.harvard.edu/abs/2019arXiv190410286S)。左图为机器学习生成的类哈勃极深场的星系图像,右图为真实的哈勃极深场的星系图像。就算专业的观测天文学家也无法只靠肉眼观察就确定地分辨出哪个是真实观测数值仿真的结果。生成尽可能真实的数值模拟图像有助于天文学家测试和校正数据处理软件和科学建模软件。以前应用传统方法生成模拟图像的时候,如何提高运行效率和数据真实性是最另人头疼的问题,现在看来机器学习的方法有望一举攻克这两个难关。
为了规避监督学习的缺点,天文学家们开始越来越关注非监督学习,并应用于星系分类(图3),引力透镜查找(图4),罕见天体探测等项目中。非监督学习的优点是不需要训练样本,从而避免了由于训练样本偏差而导致的预言偏差,而且避免了大量的重复性工作,计算效率也相对高些。但是抛弃训练样本所带来的最直接影响就是准确率会降低,而且没有标签的情况下,非监督学习的分组权重会高度依赖于分析样本中各种天体的占比,这使得非监督学习的应用范围受到了限制。尤其是对某些特性不是很强的天体的查找,天文学家们更倾向于使用监督学习的方法。
近期,一种被称作半监督学习的方法渐渐走入了天文学家们的视野,构建这个方法的目的是为了结合前面两中方法的优点并抑制它们的不足。基本思想是不完全抛弃监督学习的训练样本,而是通过标记已知天体来构建训练样本,这样既避免预测结果受通过数值模拟生成的训练样本的潜在偏差的影响,又省去了重复性工作,而且引入训练样本还能提高分类的准确率,还可以通过人为标记来为原来的非监督学习制定一定的目的性。不过天文学家们对应用半监督学习的研究才刚刚开始,可以想象,随着相关研究的逐渐深入,半监督学习在天文学中会大有可为。
4. 总结
Euclid和LSST等大尺度巡天设备的逐渐投入使用标志着大数据天文学时代的正式到来,机器学习也将成为天文学家处理数据、提取信号、科学建模等过程中不可或缺的工具。同时,5G时代的移动互联网技术也会将人机结合推向一个新的高度,因此,未来在天文学和各种新技术的碰撞中,我们有理由期待更多。也许有一天,人类真的会和Wall-E相伴而坐,仰望着那片深蓝的星空,回忆着曾经一起探索宇宙的峥嵘岁月。
作者:李楠,现英国诺丁汉大学博士后研究员。2013年于中国科学院国家天文台获得天体物理学博士学位,研究领域是宇宙学,集中在引力透镜数值模拟、机器学习以及公众科学在天体物理中的应用等课题。![]()


福建长汀中复村:红色热土绘新卷

“大美中国·西部如歌”国际音乐故事会在重庆举行